
Eclairage scientifique – Organiser et transformer l’information
1, 2, 3, codez ! - Eclairage scientifique - Organiser et transformer l'information
Organiser l’information
Ces principes permettent de représenter de petits objets : un nombre, un texte, une image, un son, une vidéo, ... On peut, par exemple, les utiliser pour stocker sur le disque d'un ordinateur, un seul texte, une seule image, un seul son ou une seule vidéo. Mais, bien souvent, on veut stocker sur un tel disque, plusieurs objets de cette nature. Cela mène à d'autres principes qui permettent non de représenter, mais d'organiser l'information.
Un disque est un espace sur lequel il est possible de stocker un
grand nombre de « 0 ou 1 », typiquement huit mille milliards pour un
disque d'un téraoctet. Pour pouvoir y stocker plusieurs textes,
images, ... on commence par découper cet espace en plusieurs zones
appelées "fichiers" qui permettent chacune de stocker un texte, une
image, un son, une vidéo, ... Mais dès que ces fichiers sont nombreux il
est nécessaire de les regrouper en dossiers, eux-mêmes regroupés en
dossiers, ... c'est-à-dire de les structurer en un arbre.
Toutefois, retrouver un fichier dans un tel arbre devient vite
difficile, si bien que l'on a inventé d'autres principes pour organiser
l'information à grande échelle. Le premier est l'utilisation de liens hypertextes.
Un tel lien permet d'indiquer, dans un premier fichier, le nom et la
position d'un second fichier situé sur le même disque, ou sur un autre.
Ainsi, on peut indiquer dans le premier fichier que le second se trouve
à l'adresse "disque3:archives/2016/lettre.txt" c'est-à-dire qu'il porte
le nom "lettre.txt" qu'il est situé dans le dossier "2016", lui-même
situé dans le dossier "archives", sur un disque qui porte le nom
"disque3". De cette manière, en utilisant un navigateur pour lire le
premier fichier, il suffira de cliquer sur ce lien pour accéder au
second. Cette manière d'organiser l'information à l'aide de liens
hypertextes, à travers un réseau de disques et d'ordinateurs, est l'idée
du Web.
Cette organisation de l'information en fichiers, puis en dossiers, et enfin enrichie de liens hypertextes est elle-même insuffisante quand on veut stocker une beaucoup d'information, et il existe deux autres manières d'organiser de grandes quantités d'information. La première, qui est adaptée à l'information structurée, est la constitution d'une base de données. Par exemple, un carnet d'adresse est une petite base de données, formée de quintuplets (5 données) constitués chacun d'un nom, d'un prénom, d'une adresse, d'un numéro de téléphone et d'une adresse électronique. Il est possible d’interroger cette base de donnée en formulant une requête, dans laquelle on demande la liste des quintuplets qui contiennent par exemple un nom, ou alors un prénom, voire un numéro de téléphone.
Pour les données moins structurées, on peut laisser en vrac un ensemble de fichiers sur un ou plusieurs disques et laisser un moteur de recherche les indexer, puis accéder à ces fichier en formulant une requête au moteur de recherche, qui indiquera alors où se trouvent tous les fichiers qui contiennent, par exemple, un certain mot. Cette manière d'organiser l'information demande moins de travail que leur structuration dans une base de données, mais donne des résultats de moins grande qualité. Chercher le numéro de téléphone de Madame Marchand en formulant une requête dans un moteur de recherche risque d'indiquer que le mot "Marchand" est présent dans de nombreux textes, dont beaucoup ne parleront que du métier de marchand.
Transformer et manipuler l’information
Représenter et organiser ainsi les informations permet de les transmettre d'un lieu à un autre (c'est-à-dire de les faire voyager dans l'espace), de les archiver pour les restituer plus tard (c'est-à-dire de les faire voyager dans le temps), mais surtout de les transformer. De nombreux algorithmes permettent de transformer des données particulières ; par exemple l'algorithme de la multiplication ne s'applique qu'à des nombres. Mais trois types d'algorithmes s'appliquent à des données quelconques : les algorithmes de compression, de correction et de chiffrement.
Compression
Nous avons vu qu'un pixel rose bonbon se représente par 11111001100001010011110 et qu'une image monochrome d'un million de pixels de cette même couleur s'obtient en juxtaposant 1 million de fois ce bloc de 24 « 0 ou 1 ». Au lieu de produire un texte très répétitif de vingt-quatre millions de signes, on peut utiliser une représentation plus concise qui consiste à indiquer que le le bloc 11111001100001010011110 doit être répété un million de fois. C'est ce que l'on appelle une compression.
Correction
Les algorithmes de correction d'erreurs permettent de repérer, et parfois de corriger, une erreur dans une information, par exemple une erreur introduite lors de la transmission de cette information. Une méthode simple, mais coûteuse en espace mémoire, est de répéter trois fois chaque information unitaire. Par exemple 101 est transformé en 111000111. Si une erreur se produit, par exemple dans le troisième triplet : 111000110, il est facile non seulement de repérer cette erreur, mais aussi de la corriger : comme il y a une majorité de 1 dans 110, la lettre initiale était sans doute un 1. Cet algorithme de correction est mis en échec uniquement quand deux erreurs se produisent dans le même triplet.
Chiffrement
Enfin les algorithmes de chiffrement permettent de rendre le texte inintelligible, sauf aux personnes qui en possèdent la clé. Une méthode simple, mais peu efficace, était déjà utilisée par Jules César pour communiquer avec ses armées. Elle consiste à décaler chaque lettre d'un nombre fixe de places dans l'alphabet. Ainsi en décalant les lettres de trois places dans la phrase "VENI VIDI VICI" on obtient "YGPL YLPL YLEL". Pour déchiffrer ce message il faut en connaître la clé, c'est-à-dire le nombre de place dont il est nécessaire de décaler chaque lettre pour retrouver le message initial. Comme il n'y a que vingt-trois lettres en latin, il n'y a que vingt-trois clés possibles, si bien que ce message n'est pas très difficile à casser (ou « cryptanaliser »), c'est-à-dire à déchiffrer sans en connaître la clé.
L’analyse fréquentielle permet de trouver rapidement la clé : dans une langue donnée, toutes les lettres ont une fréquence d’apparition connue (en français, le E – dans toutes ses déclinaisons – est de loin la lettre la plus fréquente ; les lettes A, I, N, O, R, S, T, L sont ensuite assez fréquentes… et à l’autre bout du spectre les lettres Z, W et K sont très peu utilisées). Si, dans certains cas particuliers, la lettre la plus fréquente donne directement la clé du code, il est souvent nécessaire d’utiliser un histogramme plus complet, qui fournit les fréquences de toutes les lettres. Il suffit, pour connaître la clé, de décaler l’histogramme du texte chiffré jusqu’à le faire correspondre au mieux avec l’histogramme de la langue considérée. Dans les 3 exemples ci-dessous, la clé de cryptage est toujours la même (+3, la même que celle utilisée par Jules César) : même si l’on constate de petits écarts dans les histogrammes, on retrouve un même motif (même pour le texte issu du roman « La disparition » de G. Perec qui a été écrit sans le moindre E).
| Message chiffré (clef+3) | Analyse fréquentielle | Message déchiffré |
|---|---|---|
| MH MHWWH DYHF JUDFH PRQ IHXWUH MH IDLV OHQWHPHQW O DEDQGRQ GX JUDQG PDQWHDX TXL PH FDOIHXWUH HW MH WLUH PRQ HVSDGRQ | 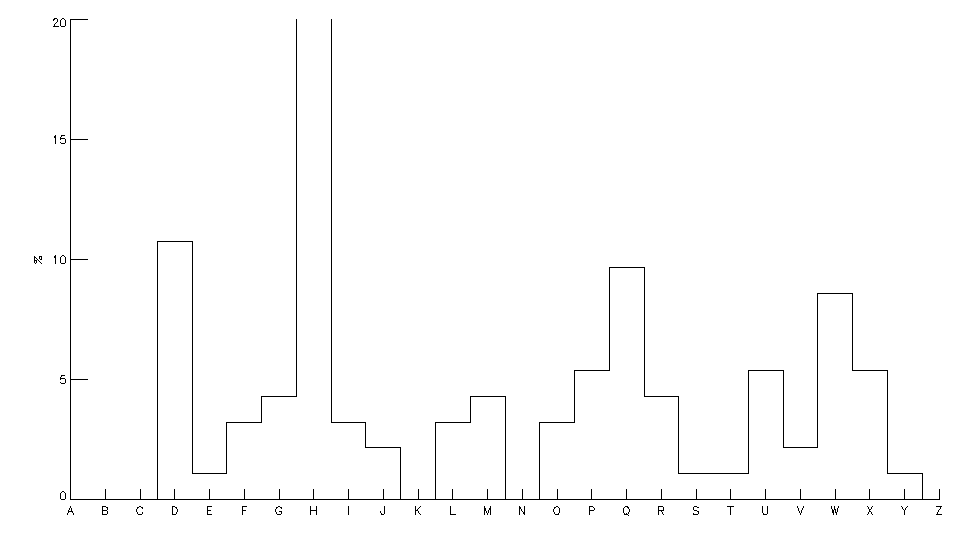 |
Je jette avec grâce mon feutre, Je fais lentement l’abandon Du grand manteau qui me calfeutre, Et je tire mon espadon (Cyrano de Bergerac, E. Rostand) |
| O HWUH KXPDLQ FURLUD WRXMRXUV TXH SOXV OH URERW SDUDLW KXPDLQ SOXV LO HVW DYDQFH FRPSOHAH HW LQWHOOLJHQW | 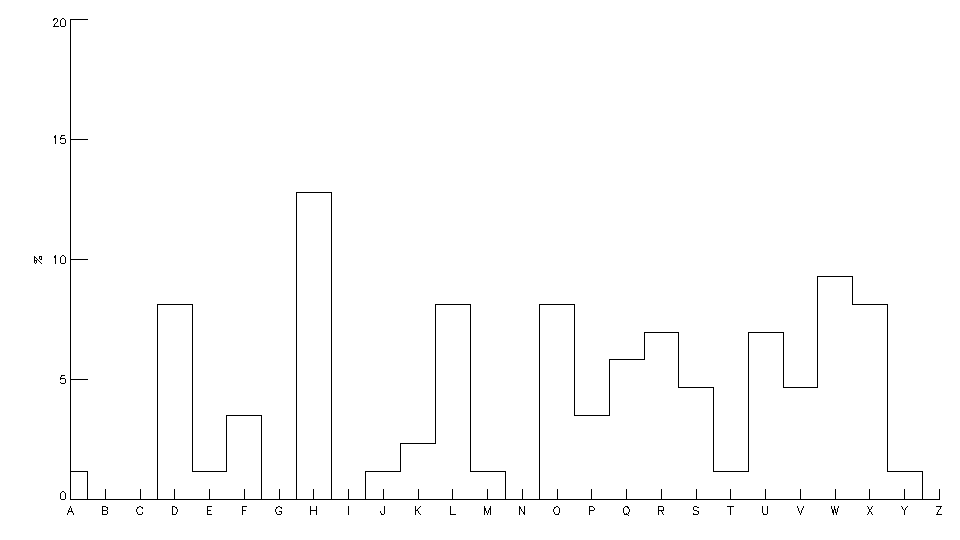 |
L'être humain croira toujours que plus le robot paraît humain, plus il est avancé, complexe et intelligent. (Les robots de l’aube, I. Asimov) |
| LO DEDQGRQQD VRQ URPDQ VXU VRQ OLW LO DOOD D VRQ ODYDER LO PRXLOOD XQ JDQW TX LO SDVVD VXU VRQ IURQW VXU VRQ FRX | 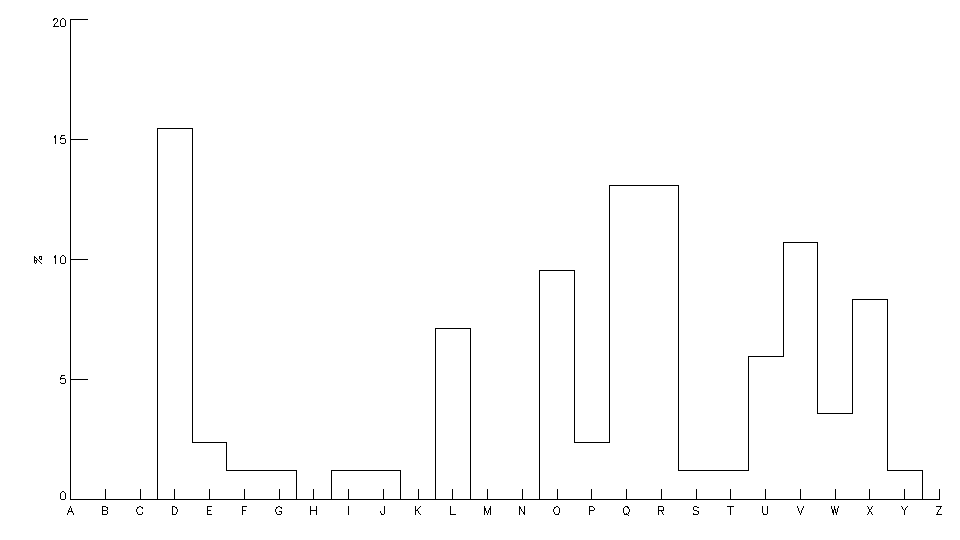 |
Il abandonna son roman sur son lit. Il alla à son lavabo; il mouilla un gant qu'il passa sur son front, sur son cou. (La Disparition, G. Perec) |
Il existe d’autres méthodes bien plus complexes que le « chiffrement par substitution monoalphabétique » : pendant la Seconde Guerre Mondiale, le chiffrement allemand Enigma (cassé par A. Turing et son équipe) se basait lui aussi sur des substitutions, mais la clef de chiffrement changeait régulièrement au fil du texte ! Historiquement, des méthodes de chiffrement qui n’étaient pas des substitutions monoalphabétiques ont aussi été utilisées, notamment en temps de guerre (par exemple, le chiffrement ADFGVX durant la seconde guerre mondiale).
Des méthodes de chiffrement bien meilleures existent et sont utilisées tous les jours pour protéger nos numéros de cartes de crédit, et autres secrets que nous souhaitons ne partager qu'avec un petit nombre de personnes…
Extrait de "1, 2, 3... codez !", Editions Le Pommier, 2016-2017. Publié sous licence CC by-nc-nd 3.0.